人型ロボットの開発に加えて各種、感覚器官についても準備を進めています。最近、沢山の兎を追いかけすぎて全てが中途半端になってきている感じが否めません。そこで何とか1つでも成果を出すために結構、集中して進めた、視覚を手に入れる準備です。
将来的な展望まで含めれば、視覚を手に入れて立体認識、障害物回避、軌道予測、人物の認識とやりたいことが沢山ありますが、今回は、人物認識として顔認証をRaspberryPi 4Bにカメラを接続してやってみました。
Raspberry Pi カメラの接続
視覚を手に入れるにはカメラが必要です。最終的には2眼ステレオカメラにしたいので、この機会にサブのCPUとして、Raspberry Pi Zero 2W を購入しました。少し話題が逸れるのですが、実はこのRaspberry Pi Zero 2W は、2台目で1台目は、Wifiの初期不良で返品しました。2台目は、おそらく使える予定ですが、OpenCVのインストールに異常に時間がかかっているので、中断してまずは、Raspberry Pi 4B で進めることにしました。
カメラは、以下のものを購入しました。純正ではないのですが、まずは最低限のことが試せれば良いということで、比較的安価なものを2個同時に購入しました。

この写真では、既にRaspberry Pi 4B とカメラが繋がっていますが、この後で50mmの長いフラットケーブルに交換しています。

少し注意が必要(間違えるかもしれない)のは、同じようなフラットケーブル接続できるDisplayと書かれている端子があります。基板にCAMERAと書かれている方に繋がないと動かないです。

長いケーブルに交換しました。おそらくRaspberry Pi 4B は、胸の辺りに装着予定なので眼には、少し距離があることになりそうです。従って、長めのフラットケーブルを予め装着することにしました。

とりあえず、付属のスタンドを取り付けました。おそらく、この茶色の保護シートは、剝すものなのだと思いますが、相当な根気が必要そうなのでチャレンジしませんでした。最終的にはロボットの眼として利用するので、このスタンドは使わないです。
OpenCVのインストール
ハードウェアの準備はできたので、続いてソフトウェアの準備を行っていきます。
まずは、OpenCVをインストールします。Python版のみを利用する想定なのでopencv-pythonをインストールします。
sudo pip install opencv-python
少し時間がかかりますが、じっくりと待ちました。
実は、Raspberry Pi Zero 2W の時は、この操作でフリーズして終わらなかったので、少し心配にはなりましたが、Raspberry Pi 4B では、問題ありませんでした。
続いて、Raspberry Pi の設定、インターフェースのところにあるカメラを有効にするという手順だと思ったのですが、カメラがありません。
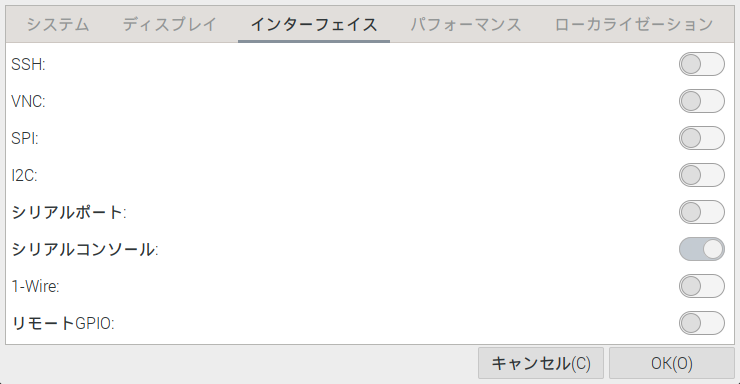
仕方がないので、別の方法でカメラを有効にしました。
sudo raspi-config
このコマンドでクラシックな設定画面を開いて設定しました。
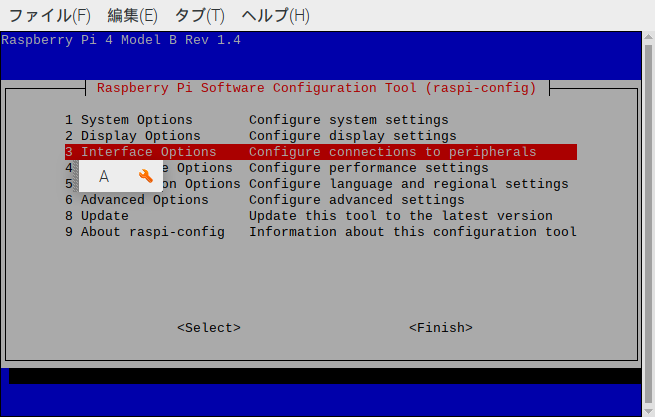
最初の画面では、「3. Interface-Options」を選択します。↑↓のカーソルとEnterで操作できます。
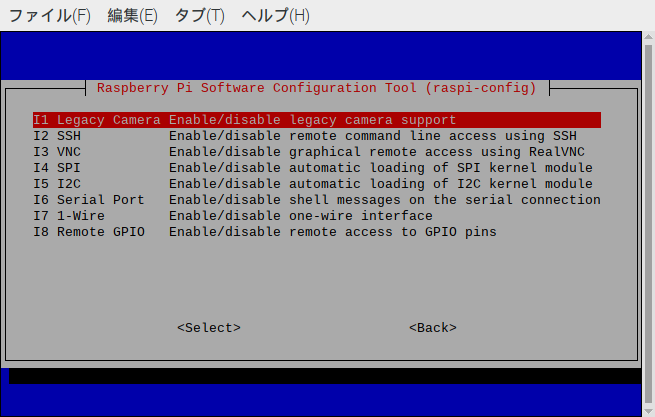
次の画面では、「I1 Legacy Camera Enable」を選択します。
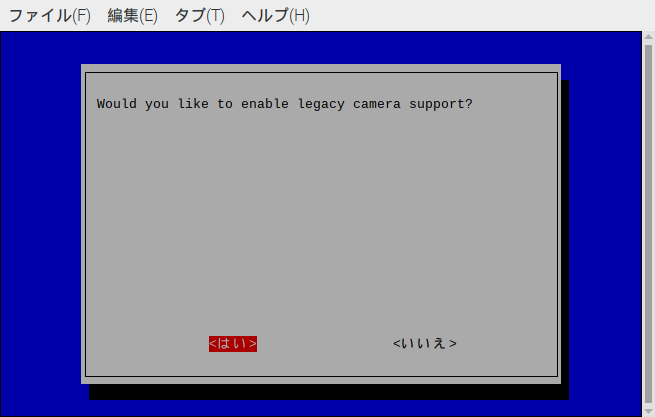
有効にする「はい」を選択します。
少し不穏なメッセージが表示されますが、他に回避策が提供されてないので無視して進みます。
はい。リブートします。
設定してリブートしても、カメラメニューが表示される訳ではありませんでした。とりあえずカメラを認識しているのかを確認します。
vcgencmd get_camera上記のコマンドを入力してカメラを認識しているか確認します。
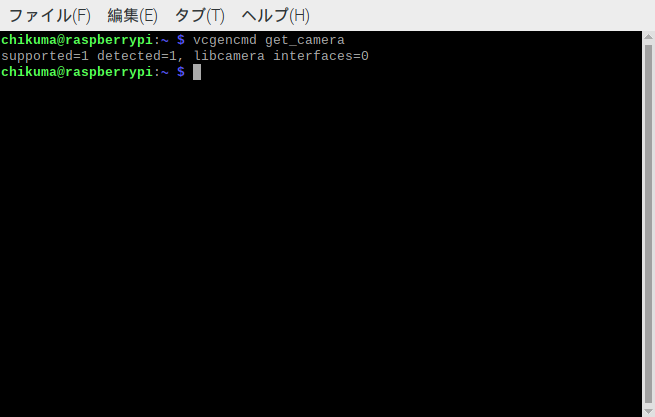
supported=1 detected=1 と表示されましたので認識しているようです。
ls -l /dev/video*
crw-rw----+ 1 root video 81, 5 5月 11 11:11:46 /dev/video0
…また、デバイスについても確認します。上記のように表示されいるので認識しているようです。
ついでに必要な他のソフトもインストールしてしまいます。まずは、顔認証に必要なface_recognitionを入れます。こちらもある程度、時間がかかります。
pip install face_recognition
続いて画像処理ユーティリティをインストールします。
pip install imutilsこれで必要なソフトウェアは、インストールが終わりました。
ちなみに、どこにインストールされたのかってなかなか分かりませんよね。でも、聞くのも基本すぎて少し恥ずかしいです。最初は、あちこちのフォルダを闇雲に探し回りましたが、以下のコマンドで一発で見つけることが出来ることを知りました。(ほとんどの人が知っているのだと思いますが…)
pip show <パッケージ名>
例) pip show opencv-pythonプログラミング
今回は、顔認識ということで少しコード量が多くなると思います。最終ゴールを決めて作っていかないと迷子になりそうなので、ゴールを決めて次の流れでプログラムを作っていきたいと思います。
- 認識対象の画像を準備するためのプログラム(head_capture.py)
- 準備した画像で人物モデルを作成するプログラム(train_model.py)
- カメラに映った映像から人物を特定し、挨拶するプログラム(facial_req.py)
基本的には、ベースとなるプログラムは、WebやGitHub等で探して少し改編をして使っています。全く改編なしに利用すべきだろうか、とも思いましたが、1.色々試して内容を理解したい。2.自分の環境ではそのままでは使えなかった。という理由で改編を加えました。
ちなみに開発時のフォルダ構成は、以下のようになっています。
~/robotics … ロボット関連のプログラム全般
~/robotics/camera … 今回の視覚関連プログラム(後にvisionに変更予定)
~/robotics/data … 画像や学習データ保存場所
~/robotics/model … opencvのモデル(カスケード分類器データ等)
~/robotics/voice … 以前、作成した声関連プログラムとライブラリimport os
import cv2
from datetime import datetime
# /dev/video0
DEV_ID = 0
# 解像度
WIDTH = 640
HEIGHT = 400
# 顔認識の最小サイズ
MIN_SIZE = (150,150)
# 顔の枠線および文字の色
FRAME_COLOR = (0, 255, 255)
# 学習済モデルの読み込み
cascade = cv2.CascadeClassifier("../model/haarcascade_frontalface_default.xml")
# Videoキャプチャの作成
cap = cv2.VideoCapture(DEV_ID)
# 解像度の指定
cap.set(cv2.CAP_PROP_FRAME_WIDTH, WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, HEIGHT)
# 名前を入力してもらう
person_name = input("Please enter your name: ")
# フォルダが存在してなければ作成する
data_dir = "../data/" + person_name
if os.path.isdir(data_dir):
print("Directory already exists: " + data_dir)
print("Save the capture image in this directory.")
else:
os.mkdir(data_dir)
# 入力するキーの説明
print("Press space-key to save the captured image.")
print("Press esc-key to exit the program.")
# メインループ
while True:
ret, frame = cap.read()
if ret:
# 上下反転させる
frame = cv2.flip(frame, 0)
# グレースケールにする
img_gray = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
lists = cascade.detectMultiScale(img_gray, minSize=MIN_SIZE)
if len(lists):
# 顔を囲む
for (x,y,w,h) in lists:
cv2.rectangle(frame, (x,y), (x+w,y+h), FRAME_COLOR, thickness=3)
# 名前を描画
cv2.putText(frame,text=person_name,org=(x,y-16),fontFace=cv2.FONT_HERSHEY_PLAIN,
fontScale=1.2,color=FRAME_COLOR,thickness=2,lineType=cv2.LINE_8)
# GUIに表示
cv2.imshow("Camera", frame)
else:
break
# キー入力チェック
key = cv2.waitKey(1) & 0xFF
if (key == 27):
# ESCキーならループを抜ける
print("Good bye video capture.")
break
if (key == 32):
# スペースキーならキャプチャ画像の保存
date = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
path = data_dir + "/" + date + ".jpg"
cv2.imwrite(path, frame)
print("JPEG Image file saved: " + path)
#後片付け
cap.release()
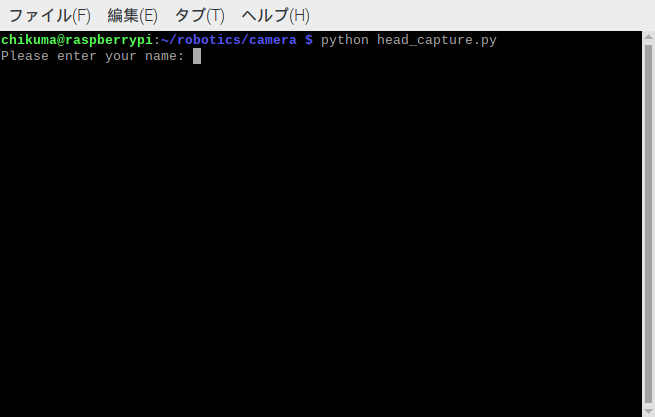
cv2.destroyAllWindows()カメラを装着したRaspberry Pi 4B で実行すると、以下のように表示されます。「Please enter your name:」と表示されるので「suzu」と入力しました。
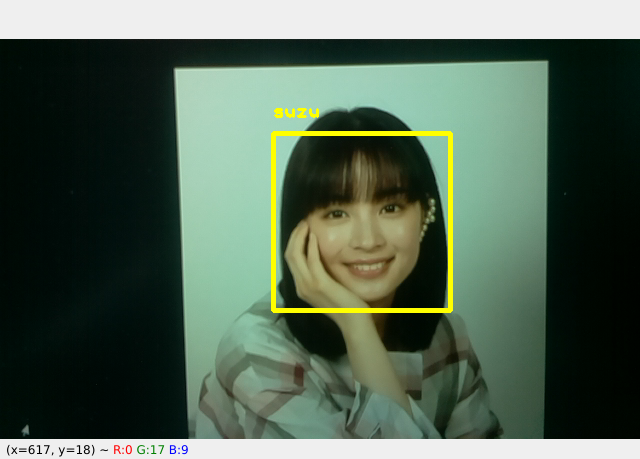
スペースキーを押すとキャプチャ画像を残します。ESCキーを押すとプログラムを終了します。
続いて学習を行います。
from imutils import paths
import face_recognition
import pickle
import cv2
import os
# 画像の保存されているディレクトリへのパス
print("[INFO] start processing faces...")
imagePaths = list(paths.list_images("../data"))
# 結果格納用の配列
knownEncodings = []
knownNames = []
# パスの中の全フォルダをスキャンする
for (i, imagePath) in enumerate(imagePaths):
# フォルダ名が名前というルール
name = imagePath.split(os.path.sep)[-2]
print("[INFO] processing image {}/{}".format(i + 1, len(imagePaths)) + " target:" + name)
# 画像を読み込んでBGRからRGBに変換する
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 顔の領域を検出する
boxes = face_recognition.face_locations(rgb, model="hog")
# 顔のモデル(学習データ)を値化する
encodings = face_recognition.face_encodings(rgb, boxes)
for encoding in encodings:
knownEncodings.append(encoding)
knownNames.append(name)
# 出来た顔のモデル(学習データ)をファイルに保存する
print("[INFO] serializing encodings...")
data = {"encodings": knownEncodings, "names":knownNames}
f = open("../data/encodings.pickle", "wb")
f.write(pickle.dumps(data))
f.close()こちらは実行するとdataフォルダに保存してある画像を順番に読み込んでいき、「encoding.pickle」という学習済ファイルを作成します。
次が実際の画像認識プログラムですが、その前に見つけた相手に対して音声で挨拶するようにしたいので、挨拶するプログラムを作ります。これは「VOICEVOX」を利用します。
import sys
import os
os.chdir(os.path.expanduser("~/robotics/voice"))
from pathlib import Path
import datetime
import voicevox_core
from voicevox_core import AccelerationMode, AudioQuery, VoicevoxCore
from playsound import playsound
from pyokaka import okaka
import time
# 声の人(WhiteCUL:たのしい)
SPEAKER_ID = 24
# OpenJTalk辞書
open_jtalk_dict_dir = './open_jtalk_dic_utf_8-1.11'
class RobotSpeaker:
def __init__(self,speaker_id=SPEAKER_ID,open_jtalk_dict_dir=open_jtalk_dict_dir,acceleration_mode=AccelerationMode.AUTO):
# 声の準備をしておく
self.voicecore = VoicevoxCore(
acceleration_mode=acceleration_mode,
open_jtalk_dict_dir=open_jtalk_dict_dir
)
self.speaker_id = speaker_id
self.voicecore.load_model(self.speaker_id)
# 最初から挨拶の音声は3種類作っておく
if (not os.path.exists("./data/good_evening.wav")):
# こんばんわの声を作っておく
text = "こんばんわ"
out = Path("./data/good_evening.wav")
audio_query = self.voicecore.audio_query(text, self.speaker_id)
wav = self.voicecore.synthesis(audio_query, self.speaker_id)
out.write_bytes(wav)
if (not os.path.exists("./data/good_moning.wav")):
# おはようございますの声を作っておく
text = "おはようございます"
out = Path("./data/good_moning.wav")
audio_query = self.voicecore.audio_query(text, self.speaker_id)
wav = self.voicecore.synthesis(audio_query, self.speaker_id)
out.write_bytes(wav)
if (not os.path.exists("./data/hello.wav")):
# こんにちわの声を作っておく
text = "こんにちわ"
out = Path("./data/hello.wav")
audio_query = self.voicecore.audio_query(text, self.speaker_id)
wav = self.voicecore.synthesis(audio_query, self.speaker_id)
out.write_bytes(wav)
def greeting(self,your_name="masutaa"):
# 時刻から挨拶ファイルを決める
now = datetime.datetime.now()
if (now.hour >= 17 or now.hour < 4):
greeting_voice = "./data/good_evening.wav"
elif (now.hour < 17 and now.hour >= 11):
greeting_voice = "./data/hello.wav"
else:
greeting_voice = "./data/good_moning.wav"
# 名前のファイル名
name_file = "./data/" + your_name + ".wav"
# まだ名前を呼んだことがなければ、名前の呼び方を生成する
if (not os.path.exists(name_file)):
# ローマ字の名前からひらがなの名前を取得する
# pip install pyokaka
your_kana_name = okaka.convert(your_name) + "さん"
out = Path(name_file)
audio_query = self.voicecore.audio_query(your_kana_name, self.speaker_id)
name_voice = self.voicecore.synthesis(audio_query, self.speaker_id)
out.write_bytes(name_voice)
# 挨拶をおこなう
playsound(greeting_voice)
playsound(name_file)
opencv_python や face_recognition では、日本語を使うことが出来ませんので、名前はローマ字で設定します。(私であれば「chikuma」、うちのママであれば「mamii」といった感じです。)画像を残したフォルダに名前が付いていますので、その名前で認識します。このプログラムでは、まず、初回起動時に「おはようございます」「こんばんわ」「こんにちわ」という3種類の音声ファイルを作成し、以降は、作成した音声ファイルを呼び出しています。
相手の名前は、ローマ字からひらがなに変換して音声ファイルを作成しています。変換は、pyokaka を利用しています。例えば「unknown」だと「うんkのwん」と訳されてしまい、そのまま読み上げます。
少し余談ですが、このプログラムは、ライブラリの認識が非常に難しく、先頭でディレクトリを移動しています。「os.chdir(os.path.expanduser(“~/robotics/voice”))」
次が実際の顔認識プログラムです。少し長めですね。(端折ったりすると結局解読できなくなると思うので長くても全文連続で載せています。)
import sys
sys.path.append('..')
from imutils.video import VideoStream
from imutils.video import FPS
import face_recognition
import imutils
import pickle
import time
import cv2
from voice.greeting import RobotSpeaker
# カメラデバイス /dev/video0
DEV_ID = 0
# 画像のサイズ(解像度)
WIDTH = 640
HEIGHT = 400
# 変数を初期化する
# 現在、認識している名前
currentname = "unknown"
# 学習済モデルデータ
encodingsP = "../data/encodings.pickle"
# openCV付属のカスケード型の顔識別器ファイル
cascade = "../model/haarcascade_frontalface_default.xml"
# 挨拶担当の声
voice = RobotSpeaker()
greetings = []
# モデルを読み込み、顔検出器を準備する
print("[INFO] loading encodings + face detector...")
data = pickle.loads(open(encodingsP, "rb").read())
detector = cv2.CascadeClassifier(cascade)
# ビデオ撮影を開始する(/dev/video0)
print("[INFO] starting video stream...")
vs = VideoStream(src=DEV_ID).start()
# ビデオ撮影開始を少し待つ
time.sleep(2.0)
# フレームレート計測を開始する(元のソースを残しているだけ)
fps = FPS().start()
# メインループ
while True:
# ビデオ撮影した静止画を取り出す
frame = vs.read()
# 解像度を調整する
frame = imutils.resize(frame, width=WIDTH, height=HEIGHT)
# 上下反転させる(RaspberryPiに取り付けたカメラが上下逆になっているため)
# TODO: ロボットに装着したときには上下正しく取り付けを行う
frame = cv2.flip(frame, 0)
# 静止画をグレースケールとRGBに変換する
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 顔の領域を抽出する(四角を付ける)
rects = detector.detectMultiScale(gray, scaleFactor=1.1,
minNeighbors=5, minSize=(30,30),
flags=cv2.CASCADE_SCALE_IMAGE)
# 四角形の配列を作る
boxes = [(y, x + w, y + h, x) for (x, y, w, h) in rects]
# 画像の符号化(モデルとの比較可能な形に変換)
encodings = face_recognition.face_encodings(rgb, boxes)
# 検出した名前の配列を初期化
names = []
# 検出した顔領域で検出を行う
for encoding in encodings:
# 画像を符号化したものと、学習済モデルとを比較する。
matches = face_recognition.compare_faces(data["encodings"], encoding)
name = "Unknown"
# マッチイングしたモデルでループする(複数検出可)
if True in matches:
# マッチングしたモデルでインデックスを取り出す
matchedIndxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# インデックスでループする
for i in matchedIndxs:
# 名前を取り出す
name = data["names"][i]
# 名前が出た回数をカウントアップする
counts[name] = counts.get(name, 0) + 1
# カウント数が最大の名前を抽出する
name = max(counts, key=counts.get)
# 現在、メインで認識している名前が変わったら現在認識している名前を書き換える
if currentname != name:
currentname = name
print("your name is " + currentname)
# 今回、初めての追加の場合は、挨拶をする
if (not name in greetings):
voice.greeting(name)
greetings.append(name)
# 名前のリストに追加する
names.append(name)
# 顔を囲む四角と名前を画像に出力する
for((top, right, bottom, left), name) in zip(boxes, names):
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 255), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.8, (0, 255, 255), 2)
# 作った画像を表示する
cv2.imshow("Facial Recognition is Runnning", frame)
# キーボード入力を取得する
key = cv2.waitKey(1) & 0xFF
# キーボードにESCが入力されたら修了する
if (key == 27):
break
fps.update()
fps.stop()
vs.stop()
cv2.destroyAllWindows()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))実行して初めて顔を検出した際に挨拶をします。時間が17時~朝4時だと「こんばんわ」、朝4時~11時だと「おはようございます」、11時~17時だと「こんにちわ」というようにしています。
顔認証プログラムを動かしてみる
実際に動かしてみました。初めての人には声の生成に少し時間がかかりますが、何だかこうやって挨拶してくれるのは、とても嬉しいですね。
声は、この小型スピーカーで出しています。
ロボット制御に関しては、次は、聴覚を手に入れたいと思います。また、少し時間がかかるかもしれないですが、Raspberry Pi Zero 2W と連動して立体認識が可能か実験をしてみたいと思っています。
以上


コメント