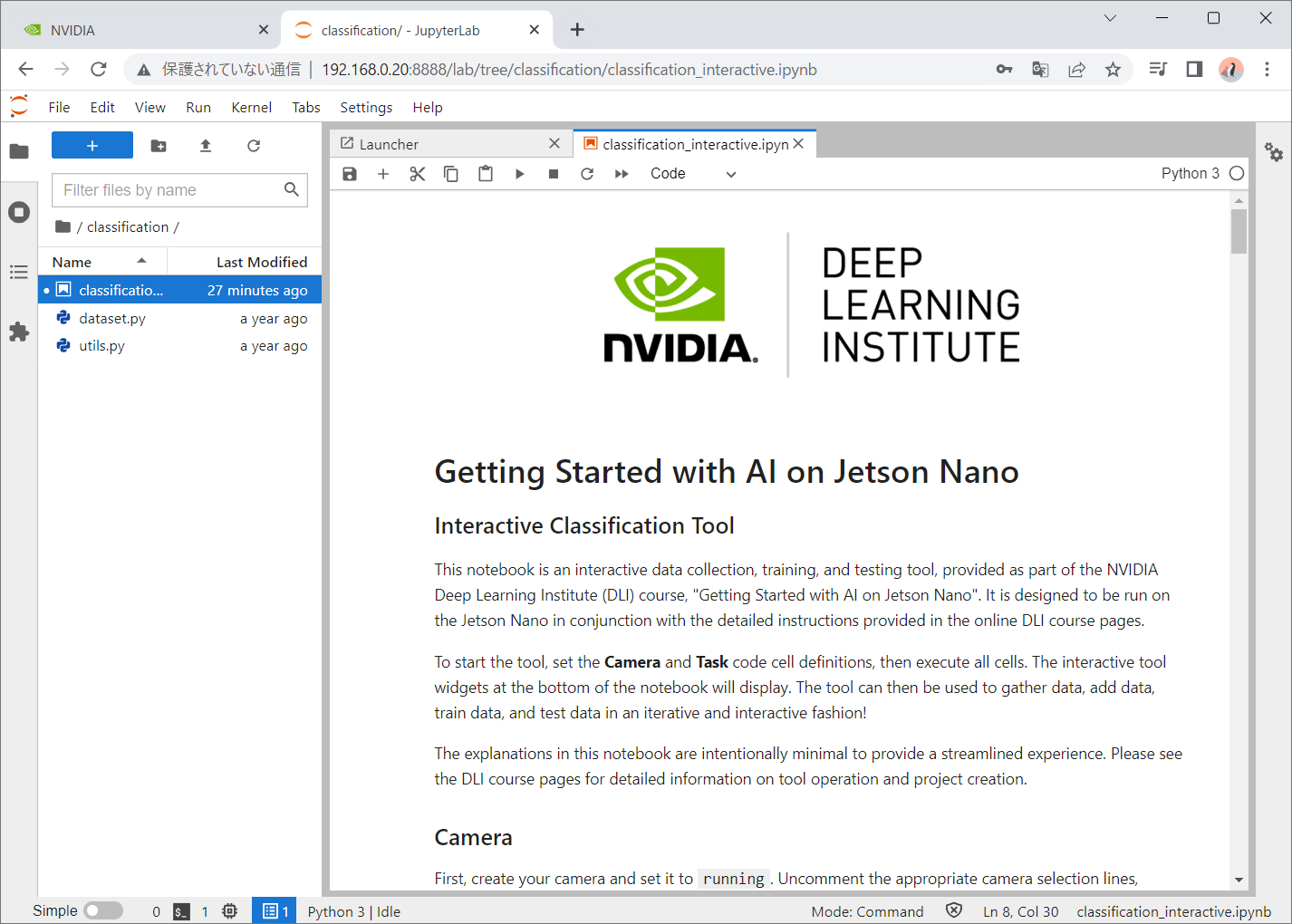
前回、購入して開発環境を構築したJetson nanoを実際に使ってみたいと思います。開発環境構築までの記事は、以下になっています。また、公開順序が逆になってしまいますが、Jetson Nano のモバイル環境構築と眼の装着についても記事を作る予定です。

公式サイトを確認してみる
まずは、日本語の公式サイトがあるので確認をしてみます。

Jetson Nano (B01) のハードウェア仕様は、以下のように記載されています。
| GPU | 128 コア NVIDIA Maxwell™ アーキテクチャ GPU |
| CPU | クアッドコア ARM® Cortex®-A57 MPCore プロセッサ |
| メモリ | 4GB 64 ビット LPDDR4 |
| ストレージ | microSD (カードは含まれていません) |
| ビデオエンコード | 1x 4K30 | 2x 1080p60 | 4x 1080p30 | 9x 720p30 (H.264/H.265) |
| ビデオでコード | 1x 4K60 | 2x 4K30 | 4x 1080p60 | 8x 1080p30 | 18x 720p30 (H.264/H.265) |
| ネットワーク | ギガビット イーサネット、M.2 Key E |
| カメラ | 2x 15 ピン 2 レーン MIPI CSI-2 カメラ コネクタ |
| ディスプレイ | 1x HDMI 2.0、1x DP 1.2 |
| USB | 4x USB 3.0 Type-A コネクタ 1x USB 2.0 Micro-B コネクタ |
| その他I/O | 40 ピン ヘッダー (UART、SPI、I2S、I2C、PWM、GPIO) 12 ピン自動化ヘッダー 4 ピン ファン ヘッダー 4 ピン POE ヘッダー DC 電源ジャック 電源、強制リカバリ、リセット ボタン |
| サイズ | 100mm x 79mm x 30.21mm (高さには、キャリア ボード、モジュール、冷却ソリューションが含まれます) |
さて起動するようになったのは、良いのですが、何をしよう…となりました。とりあえずチュートリアルをやってみます。
チュートリアルをやってみる
チュートリアルの手順を詳細に確認するためには、コース受講登録が必要になるようです。
どこから辿っても、認定を受けるというページに行き着くので素直に受講登録しました。
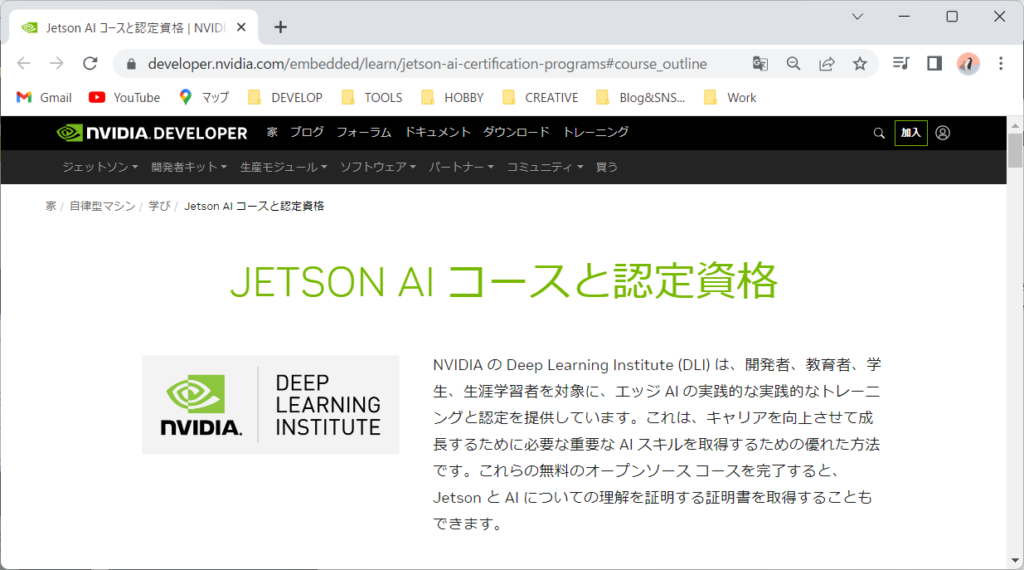
以下のサイトで動画は見れますが、詳細な解説が見れないため、コースに登録してビデオを見てコースの解説サイトを見ながらチュートリアルを行っていきました。なお、解説サイトは、英語です。
すべてのチュートリアルを一度に行うのは、大変なのでまずは、Dockerコンテナを実行し、JupyterLabのカメラテストとThumbUP/ThumbDownまで行ってみました。
Swap領域の拡張
チュートリアルでは、まずはスワップ領域(メモリの内容を一時退避する領域)を増やしているので、習ってスワップ領域を増やします。ただし、私が使用しているのはJetson Nano B01 4GBですが、チュートリアルでは、Jetson Nano 2GBを使っていました。メモリサイズが違うので手順として必須なのかは分かりません。
$ free -m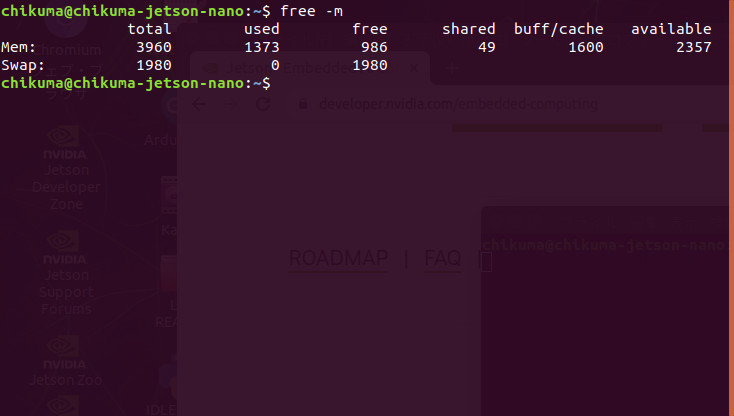
スワップ領域を2GBから4GBに増やすためのコマンドを入れます。
$ sudo systemctl disable nvzramconfig
$ sudo fallocate -l 4G /mnt/4GB.swap
$ sudo mkswap /mnt/4GB.swap
$ sudo vi /etc/fstab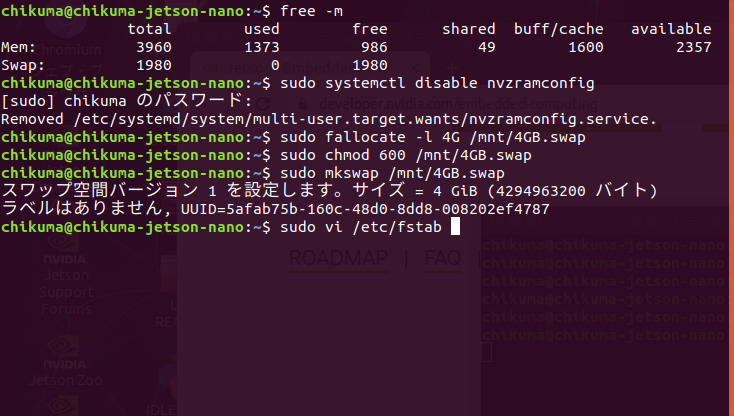
vi で /etc/fstabl を以下のように編集します。なお、viで編集モードにするには、キーボードの文字を入力する。コマンドモードにするにはESCキーを押します。
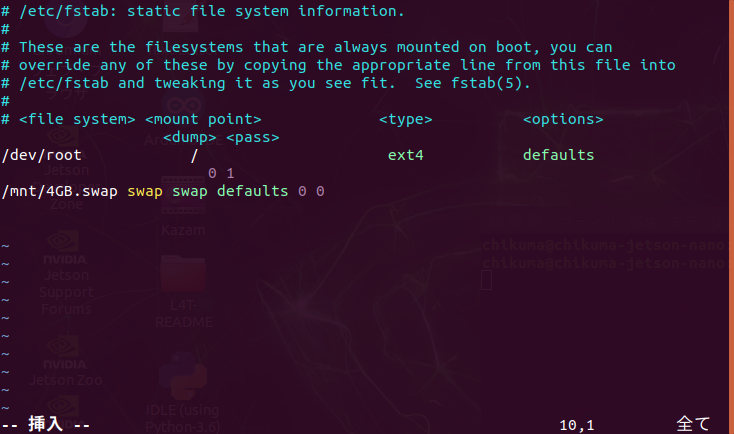
ESCキーを押して、:wq で保存して終了します。再起動後にスワップ領域を再確認してみます。
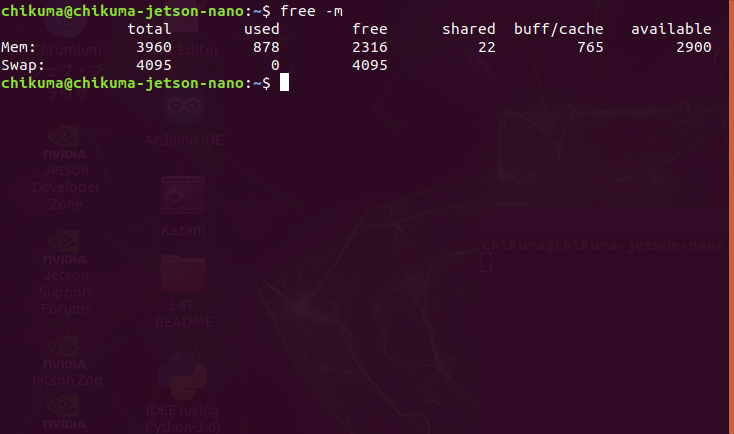
これで完了です。
Runtime Docker のダウンロード
チュートリアルに必要な各種ソフトウェアやソース、データが含まれたモジュールをDockerを使ってダウンロードします。まずはチュートリアルのサイトを開きます。(このサイトへ辿り着くのに苦労するのでブックマークを残しておくことをお勧めします)
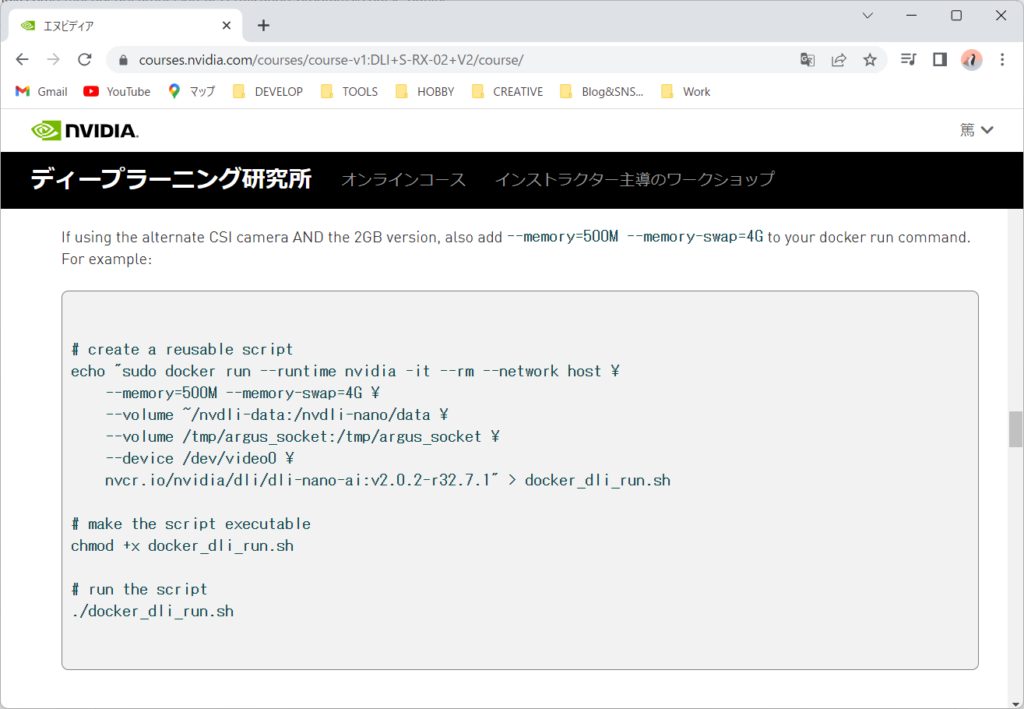
私は、CSIにカメラを接続しているので、CSIの方を実行します。なおバージョン等は、最新になっているようです。
$ echo "sudo docker run --runtime nvidia -it --rm --network host \
> --memory=500M --memory-swap=4G \
> --volume ~/nvdli-data:/nvdli-nano/data \
> --volume /tmp/argus_socket:/tmp/argus_socket \
> --device /dev/video0 \
> nvcr.io/nvidia/dli/dli-nano-ai:v2.0.2-r32.7.1" > docker_dli_run.sh
$ chmod +x docker_dli_run.sh
$ ./docker_dli_run.sh
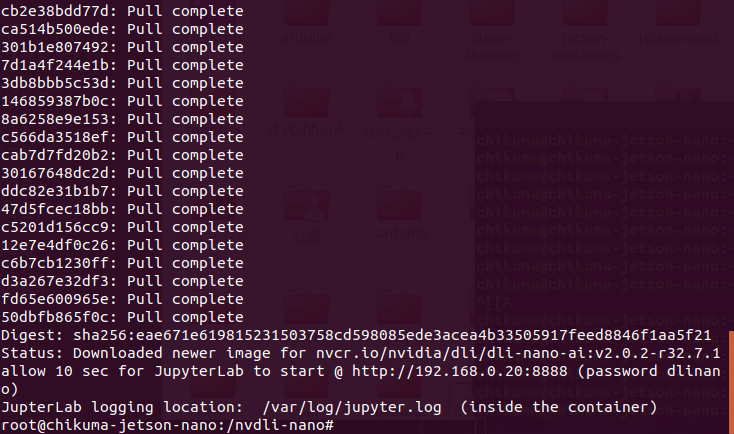
ダウンロードが完了するとJupyterLabへのアクセス方法が表示されます。ブラウザからhttp://<JetsonNanoのローカルIPアドレス>:8888 でアクセスしてパスワードに「dlinano」と入力してJupyterLabにログインします。
JupyterLabは、Webブラウザ上で動くので他のOS、PC上でも使うことが出来ます。つまり、JetsonNanoにモニタを直接接続しなくても遠隔で操作が可能になります。
カメラにアクセスしてみる
続いてカメラにアクセスしてみます。講座の「Hello Camera」を実行してみます。
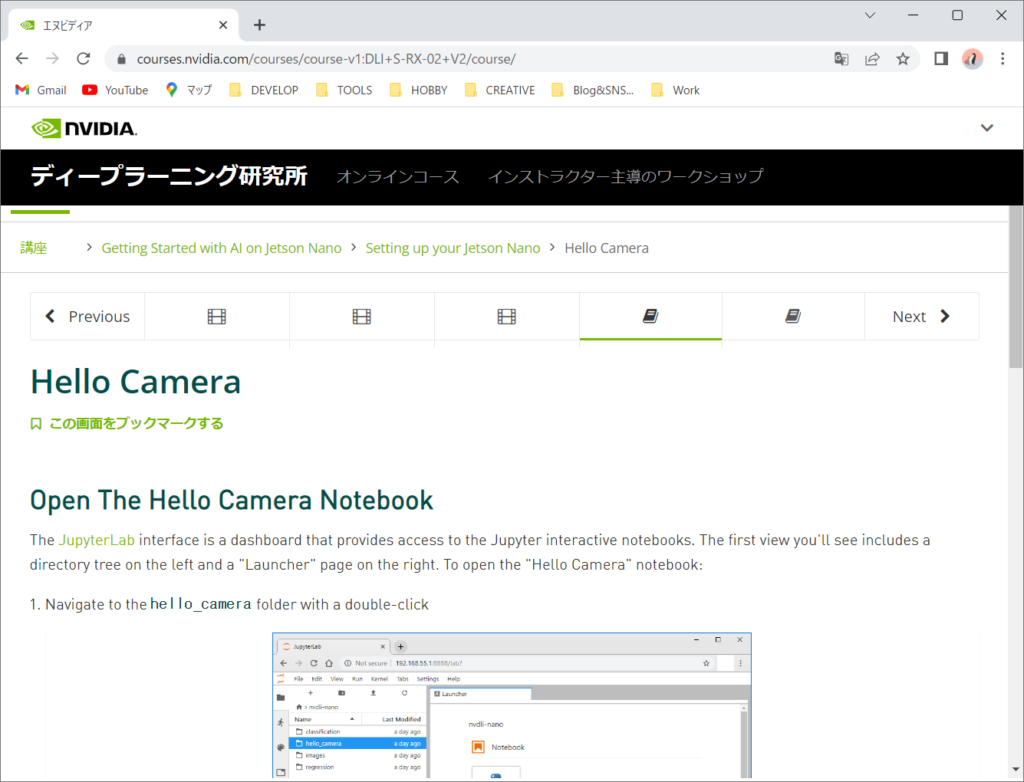
JupyterLabの左側の「hello_camera」を選択します。
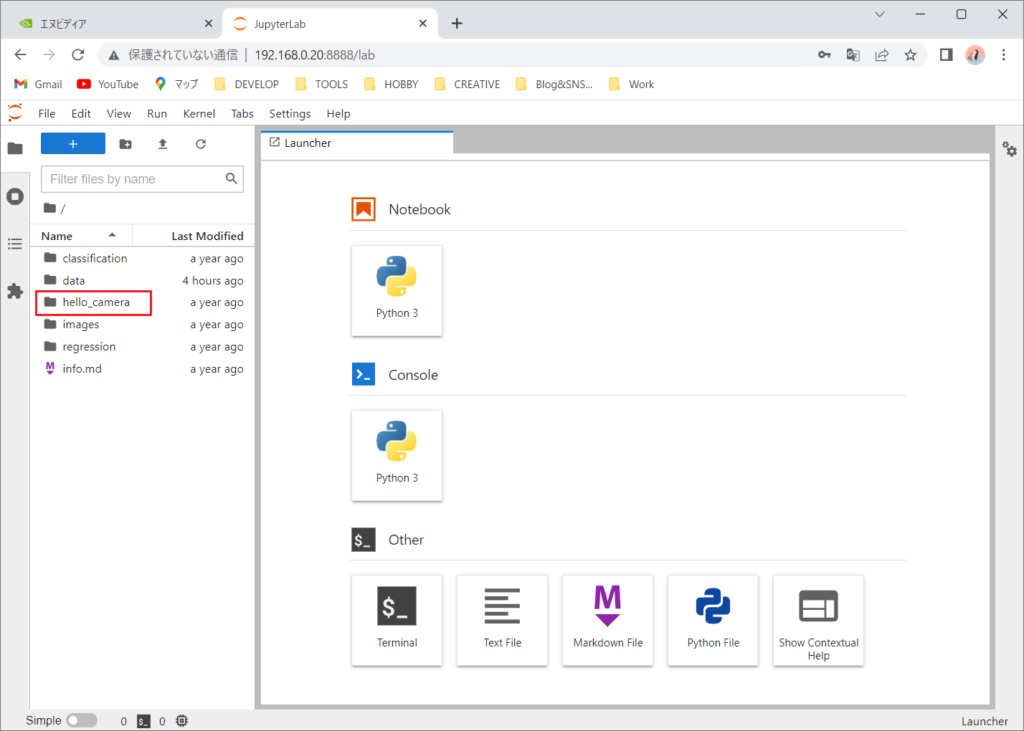
「csi_camera.ipynb」をダブルクリックして開きます。
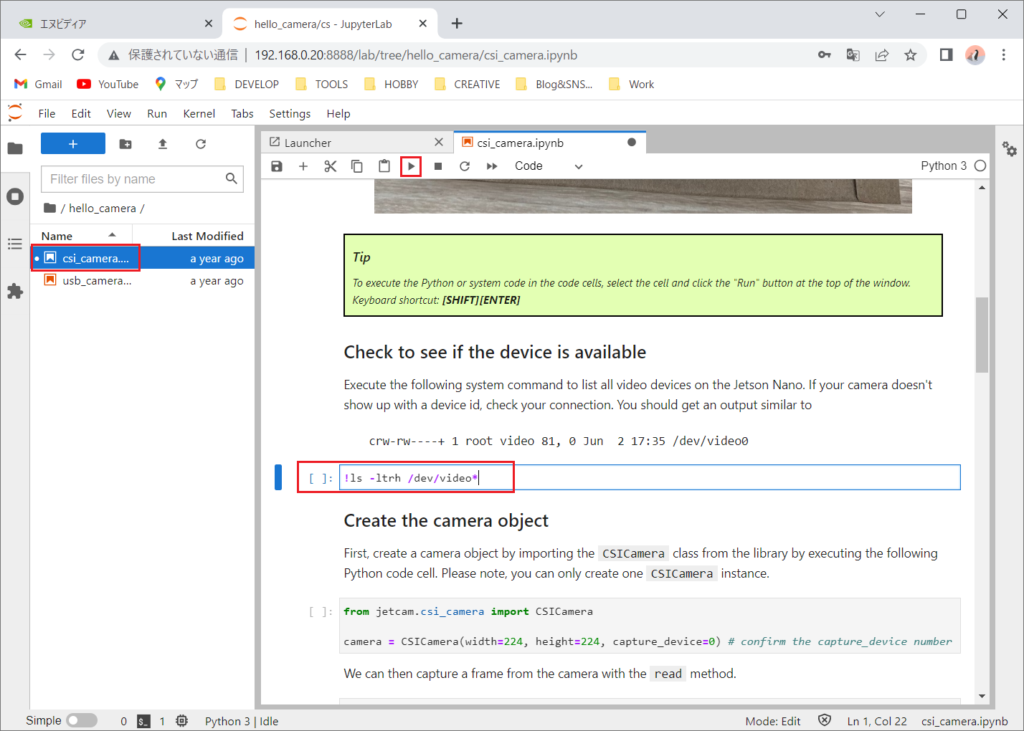
開いたページは、実行可能なコードが記載されています。コードにカーソルを合わせて、[SHIFT]+[ENTER]を押すか、「▶」ボタンを押します。
このページでは、基本的にそのまま実行していきます。「Create a widget to view the image stream」の終わりまで実行するとカメラからの動画が送られてくるようになります。
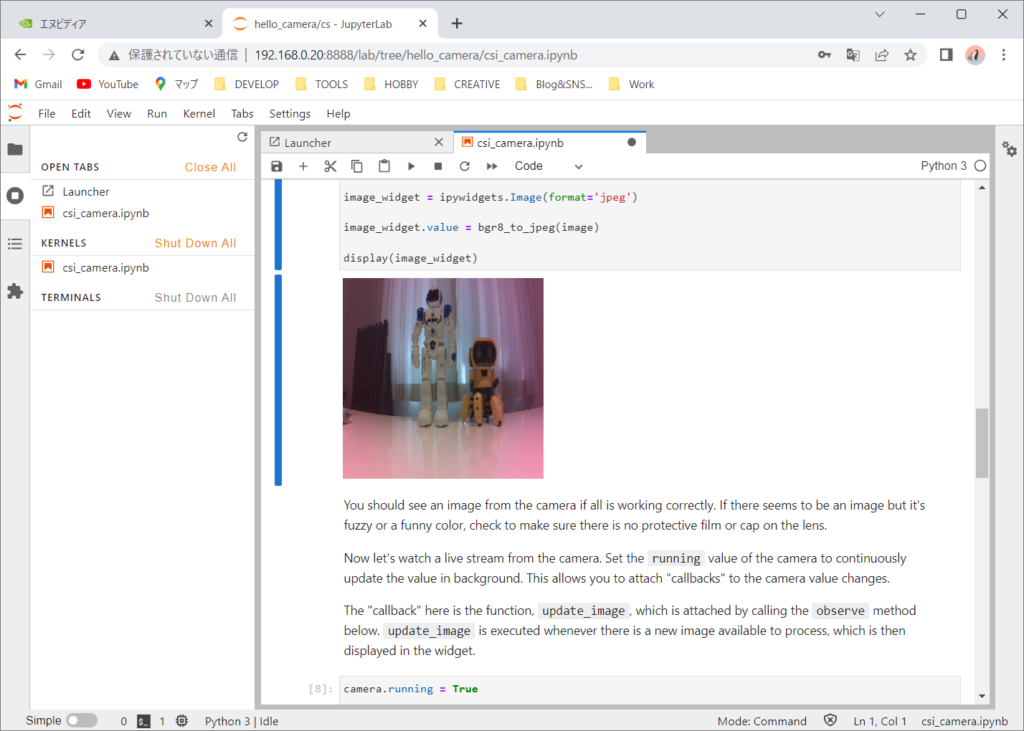
これで「Hello Camera」が終わりです。実行したままだと他のプログラムがカメラにアクセスできないので終了させます。左側の「Shut Down All」で終了させます。
画像分類(Image Classification)を実行してみる
幾つかの座学的な講座ページを読んだ後で画像分類プロジェクトを実行するページに辿り着きます。さて、ここからディープラーニングの講座になります。
JupyterLabからClassificationをJupyterNotebookで開きます。
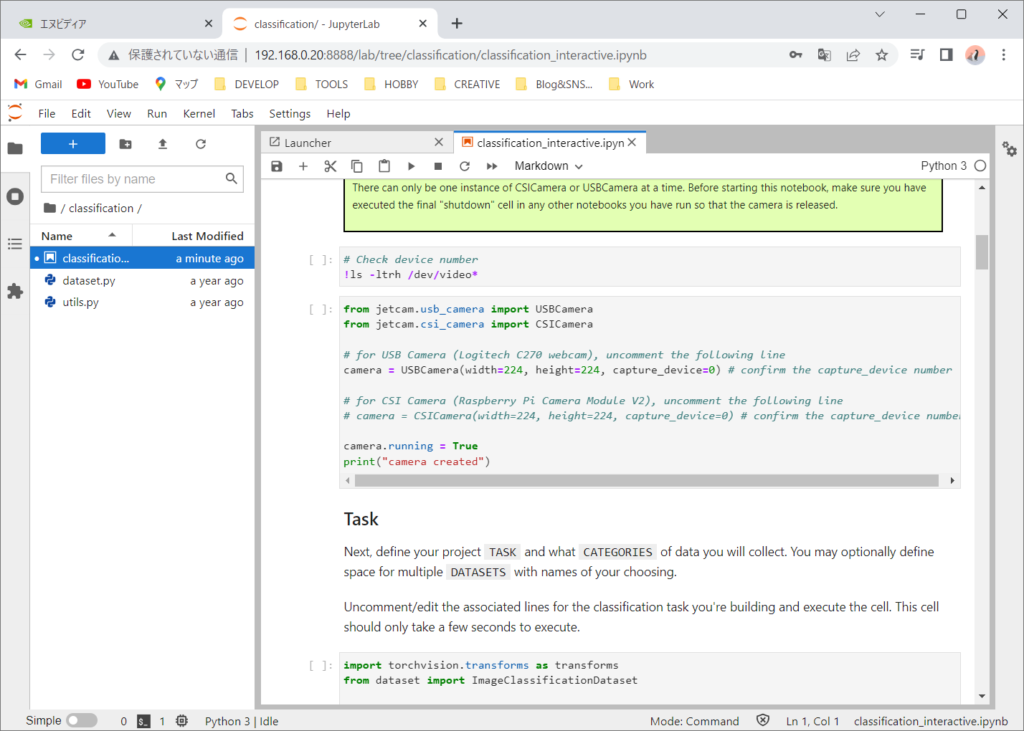
このチュートリアルは、USBカメラ、CSIカメラどちらを使うかでコメントアウトにする必要があります。私は、CSIカメラを使うのでUSBカメラをコメントアウトします。
# from jetcam.usb_camera import USBCamera
from jetcam.csi_camera import CSICamera
# for USB Camera (Logitech C270 webcam), uncomment the following line
# camera = USBCamera(width=224, height=224, capture_device=0) # confirm the capture_device number
# for CSI Camera (Raspberry Pi Camera Module V2), uncomment the following line
camera = CSICamera(width=224, height=224, capture_device=0) # confirm the capture_device number
camera.running = True
print("camera created")実行してエラーにならなければ、「camera created」と表示されます。
続いて、次のタスクを実行します。これは使用する分類器をロードしています。コメントを切り替えることで分類器の種類を変更できますが、今回は、Thumbsをそのまま使います。
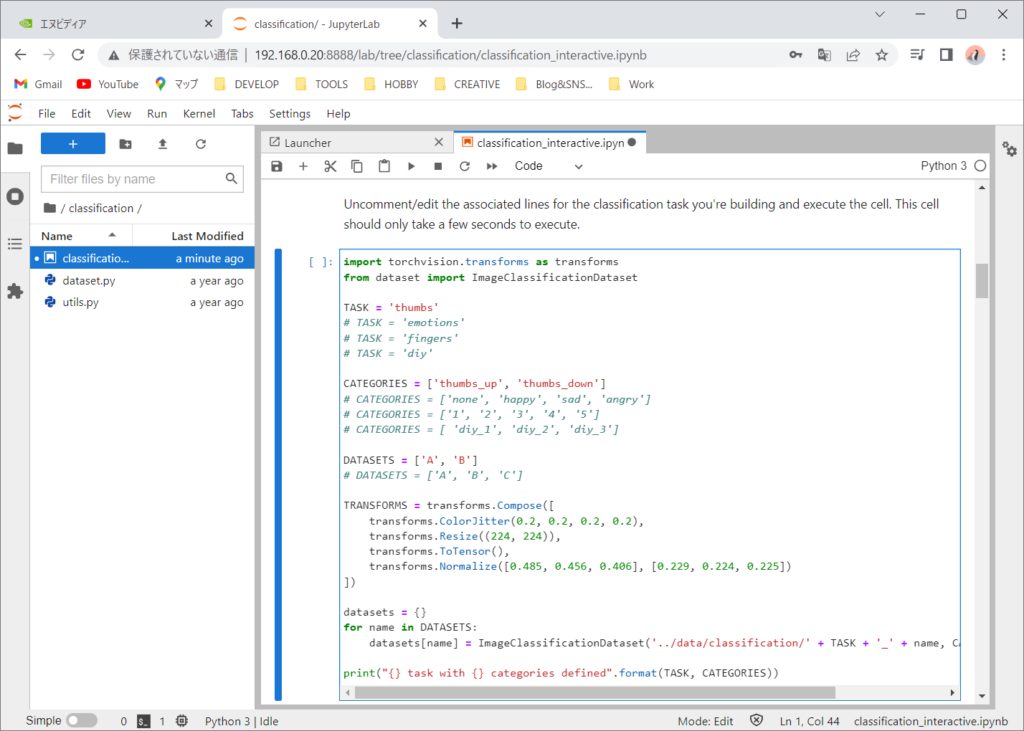
次は、データ収集ツールのためのウィジェットを作成します。(ウィジェットとはGUI部品の総称です)
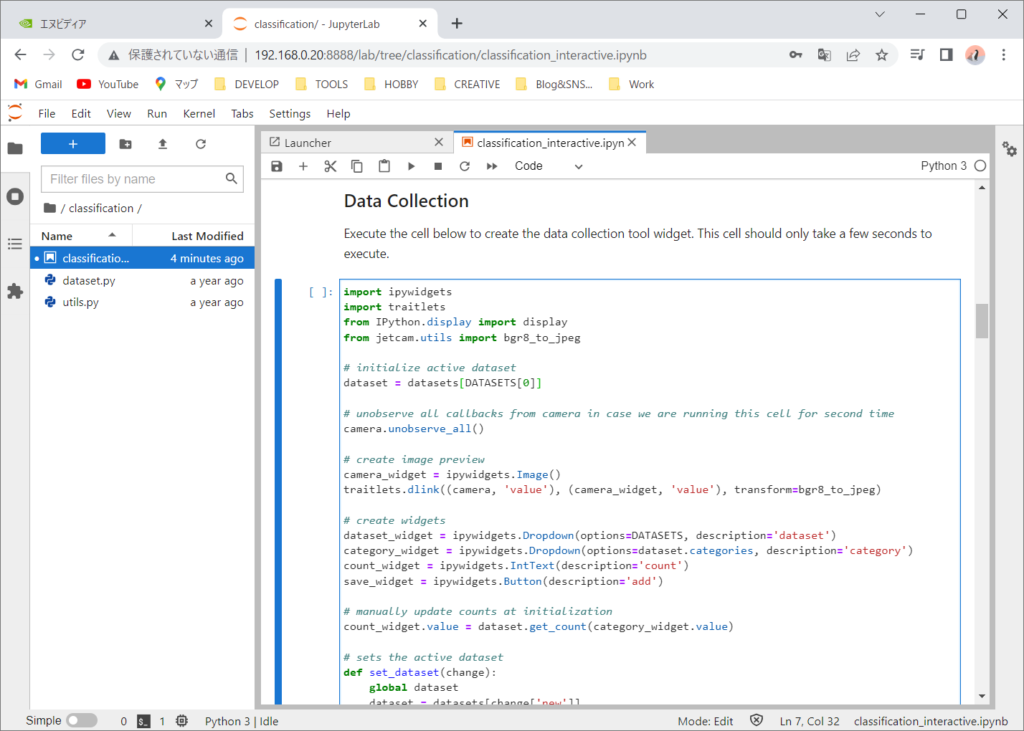
次は、ニューラル ネットワークを定義し、プロジェクトに必要な出力に一致するように全結合層 (fc) を調整します。 ここではPyTorchフレームワークを利用して、ニューラルネットワークには、ResNet18というCNN(畳み込みニューラルネットワーク)を使います。
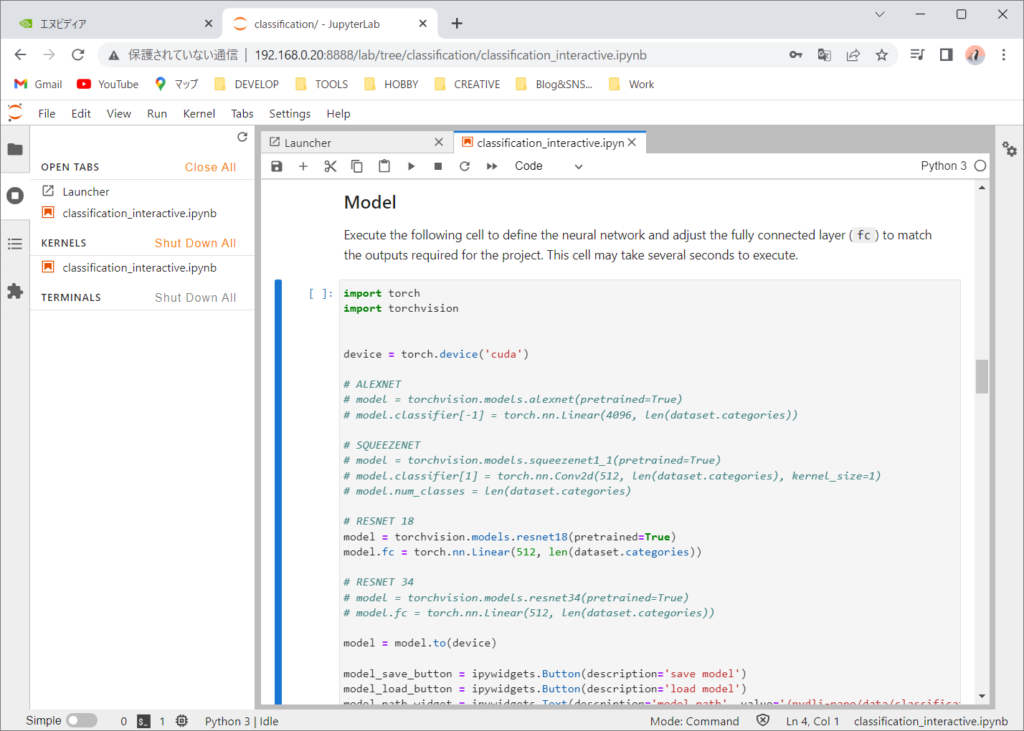
次はライブ実行ウィジェットを起動します。トレーナーとそれを制御するウィジェットを定義します。
以下でウィジェットの使い方が表示されています。が、英語なので雰囲気で使っていきたいと思います。
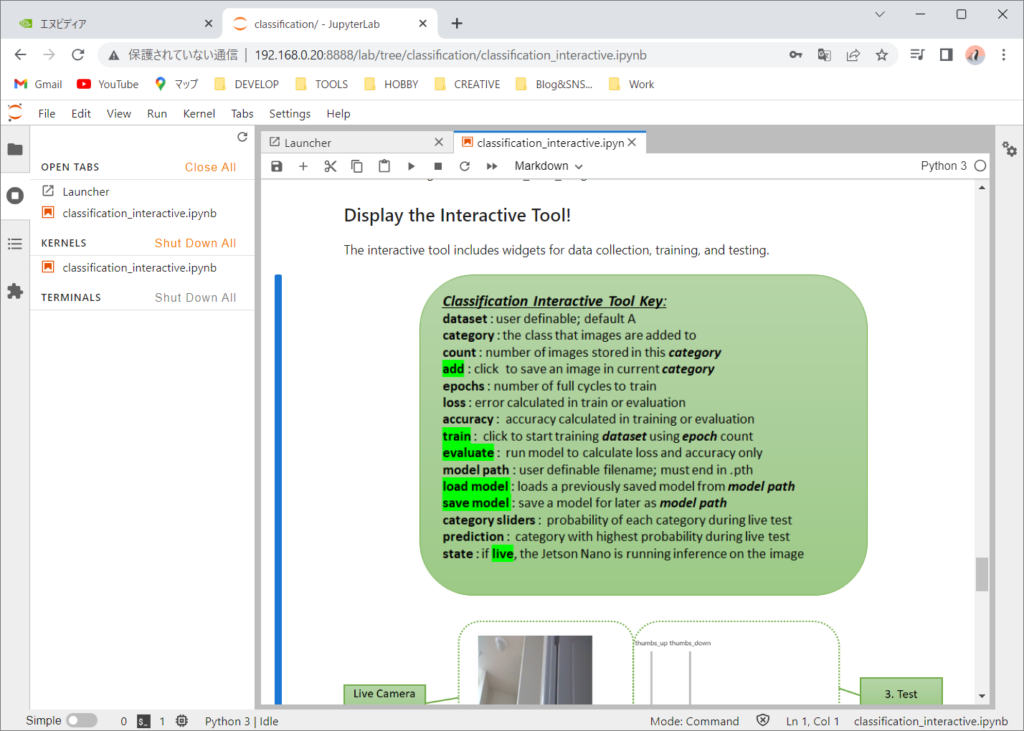
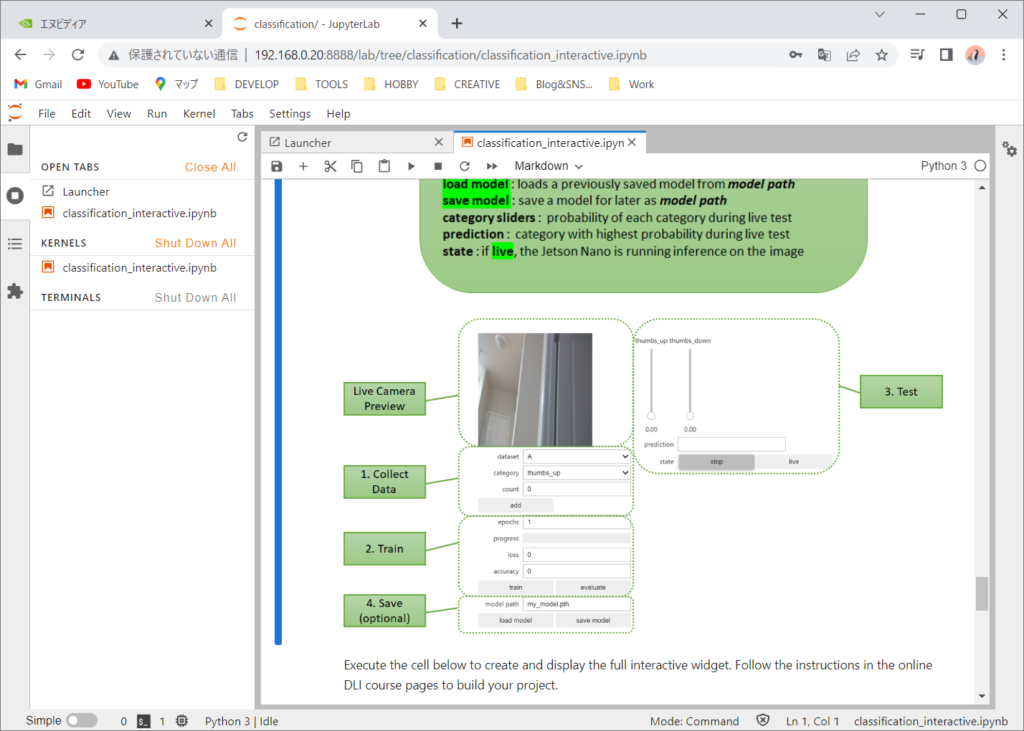
それでは、ウィジェットを表示して、学習とテストを行ってみたいと思います。
トレーニングデータを保存していきます。categoryにthumbs_upを選択しているときは、親指を上に向けた状態でaddボタンを押して追加しています。約30枚程度保存しました。次にcategoryにthumbs_downを選択して、親指を下に向けた状態でaddボタンを押して追加していきます。角度や距離などを変えて保存します。
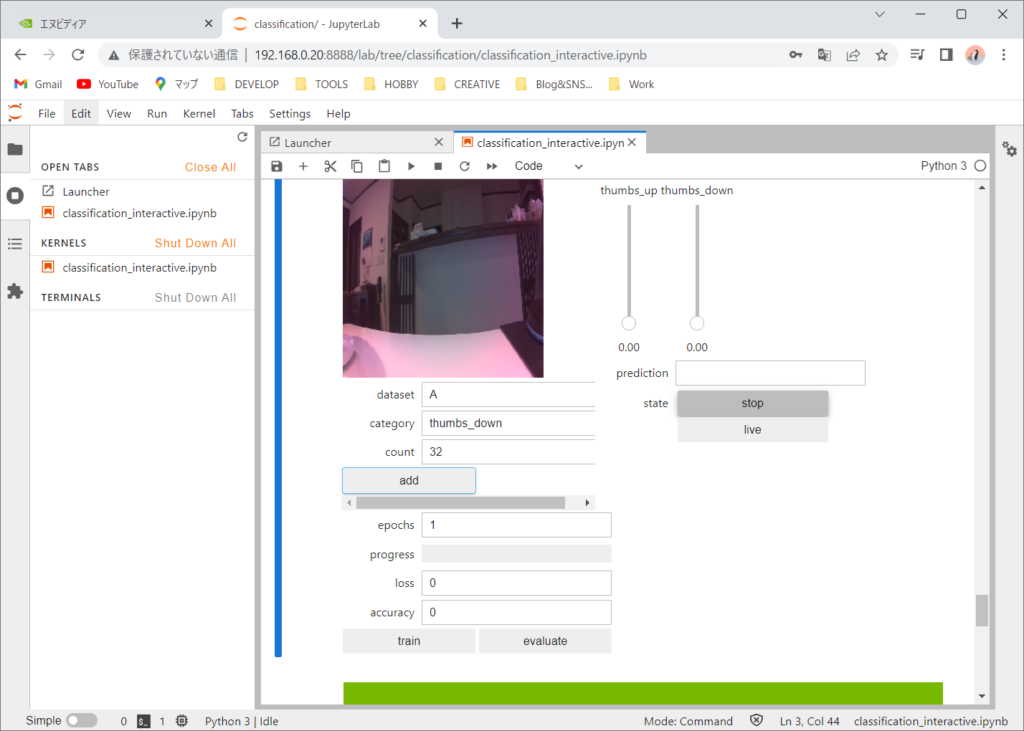
次に学習を開始します。epochsを10程度にして学習を行います。途中でaccuracyが1(100%)になります。ただし、これは与えた学習データに対してなので、どんな状態でも100%間違えず認識するという訳ではありません。
liveにして、実際にThumbs_up/Thumbs_downを試してみます。
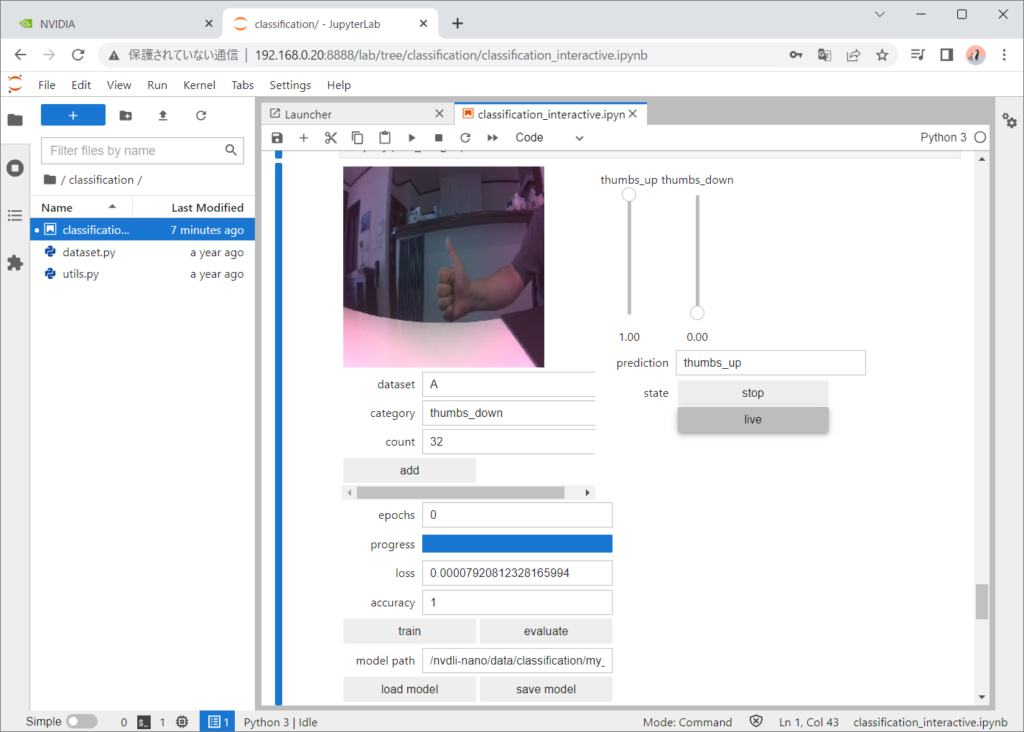
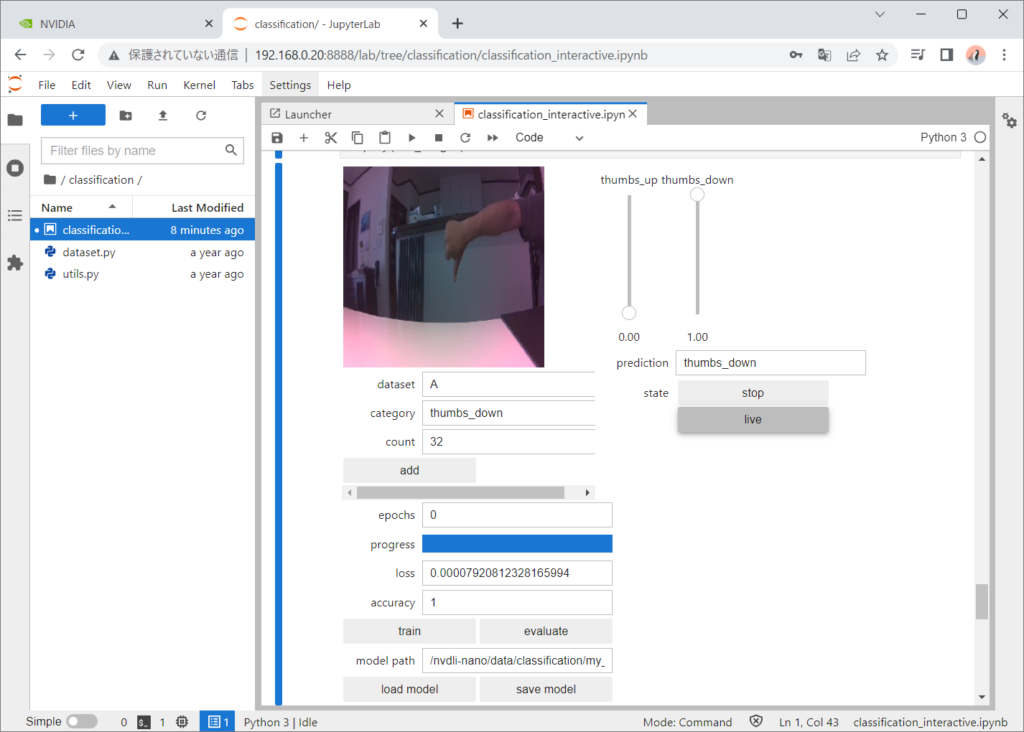
正しく認識できました。背景を変えたりして認識できない場合があるとそこで学習データを追加して、trainボタンで追加学習をすると認識できるようになります。
以上


コメント