前回は、Windows上で動いているVOICEVOXエンジンを使って声を出しましたが、やはり自分だけで声が出したいですね。少し正規の手順とは異なりますが、Rasberry PI 4B を自分で喋るように設定してみましたので、紹介いたします。

リンク
リンク
VOICEVOX_COREのダウンロードとインストール
ここは正規の手順ではないです。最終的には、Pythonで声を出すことが目的なので個別にダウンロードせずにライブラリを一括でダウンロードします。その後、Python用のバインディングをダウンロードしてセットアップします。
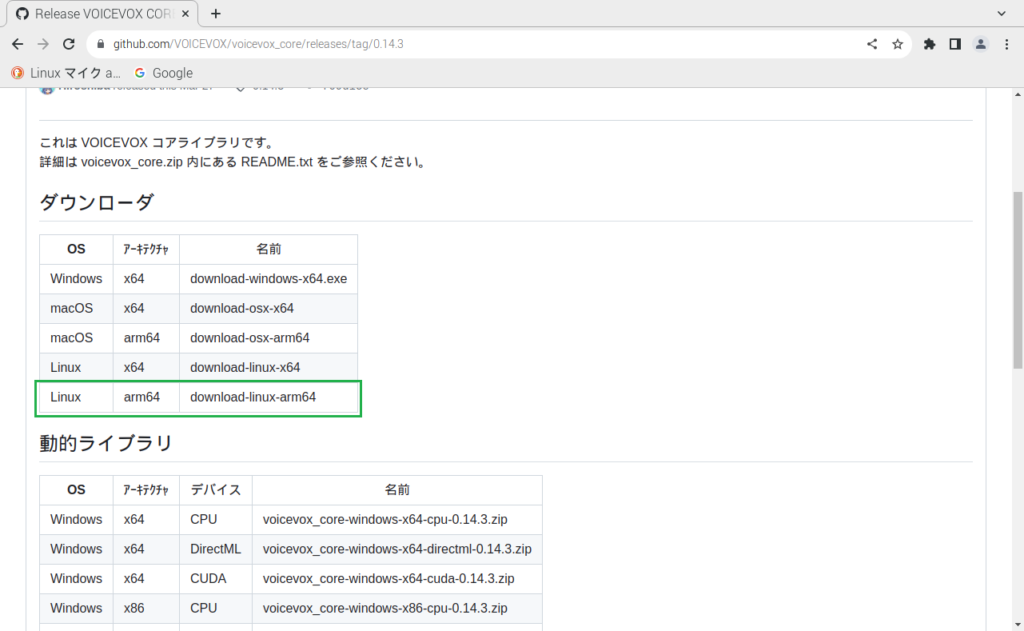
まずは、ライブラリから以下のTerminalでコマンドで入手してインストールします。
cd ~/Downloads
binary=download-linux-arm64
curl -sSfL https://github.com/VOICEVOX/voicevox_core/releases/latest/download/${binary} -o dwnload
chmod +x download
./download -o ~/voicevox_core続いてPython用のバインディングをインストール&セットアップします。
wget https://github.com/VOICEVOX/voicevox_core/releases/download/latest/voicevox_core-0.14.3+cpu-cp38-abi3-linux_aarch64.whl
pip install voicevox_core-0.14.3+cpu-cp38-abi3-linux_aarch64.whl1つ前の工程で不要なインストールファイルを削除します。
cd ~/voicevox_core
rm -rf model
rm libvoicevox_core.so他にも「README.txt」や「VERSION」などのファイルもありますが、容量もさほど大きくないので残しておきました。(ほぼmodelの中のファイルサイズです)
実際に動かしてみる
実際に動かす前にサウンド再生に必要なパッケージとライブラリをインストールします。
sudo apt install python3-gst-1.0
pip install playsoundサンプルコードとして以下のソースファイルをダウンロードもしくは作成します。SPEARKER_IDのみ0から24に変更しました。24は、WhiteCULさんの楽しい時の音声です。ダウンロードしたrun.pyは、wavファイルを保存しますが、plyasoundを使ってそのまま再生までさせます。
import dataclasses
import json
import logging
from argparse import ArgumentParser
from pathlib import Path
from typing import Tuple
from playsound import playsound
import voicevox_core
from voicevox_core import AccelerationMode, AudioQuery, VoicevoxCore
SPEAKER_ID = 24
def main() -> None:
logging.basicConfig(
format="[%(levelname)s] %(filename)s: %(message)s", level="DEBUG"
)
logger = logging.getLogger(__name__)
(acceleration_mode, open_jtalk_dict_dir, text, out) = parse_args()
logger.debug("%s", f"{voicevox_core.METAS=}")
logger.debug("%s", f"{voicevox_core.SUPPORTED_DEVICES=}")
logger.info("%s", f"Initializing ({acceleration_mode=}, {open_jtalk_dict_dir=})")
core = VoicevoxCore(
acceleration_mode=acceleration_mode, open_jtalk_dict_dir=open_jtalk_dict_dir
)
logger.debug("%s", f"{core.is_gpu_mode=}")
logger.info("%s", f"Loading model {SPEAKER_ID}")
core.load_model(SPEAKER_ID)
logger.debug("%s", f"{core.is_model_loaded(0)=}")
logger.info("%s", f"Creating an AudioQuery from {text!r}")
audio_query = core.audio_query(text, SPEAKER_ID)
logger.info("%s", f"Synthesizing with {display_as_json(audio_query)}")
wav = core.synthesis(audio_query, SPEAKER_ID)
out.write_bytes(wav)
logger.info("%s", f"Wrote `{out}`")
playsound(out)
def parse_args() -> Tuple[AccelerationMode, Path, str, Path]:
argparser = ArgumentParser()
argparser.add_argument(
"--mode",
default="AUTO",
type=AccelerationMode,
help='モード ("AUTO", "CPU", "GPU")',
)
argparser.add_argument(
"open_jtalk_dict_dir",
type=Path,
help="Open JTalkの辞書ディレクトリ",
)
argparser.add_argument(
"text",
help="読み上げさせたい文章",
)
argparser.add_argument(
"out",
type=Path,
help="出力wavファイルのパス",
)
args = argparser.parse_args()
return (args.mode, args.open_jtalk_dict_dir, args.text, args.out)
def display_as_json(audio_query: AudioQuery) -> str:
return json.dumps(dataclasses.asdict(audio_query), ensure_ascii=False)
if __name__ == "__main__":
main()実際に動かしてみます。以下のコマンドを入力して実行してみます。
cd ~/voicevox_core
python ./run.py ./open_jtalk_dic_utf_8-1.11 これはテストです ./audio.wavRasberry PI 4Bで約17秒かかりました。スムーズに話するためには、ある程度、生成済音声ファイルを組み合わせるなど考える必要がありそうですが、最初は、考えながら話すのも良いかもです。


コメント