やはりロボットには、声が必要です。できればかわいい声が良いですね。そこで今回利用するのがVOICEVOXです。無料で使える中品質なテキスト読み上げソフトウェアと書いてあります。
VOICEVOXのインストール
今回は、WindowsにVOICEBOXを入れてエンジンとして動かします。VOICEVOXは、以下の3つの主要プログラムで構成されています。
| voicevox_core | 音声合成処理を行うコアライブラリ |
| voicevox_engine | HTTPリクエスト受け取ってコアで音声合成して音声ファイルを返す。 音声合成エンジン |
| voicevox | GUIで音声を作成するエディター |
開発もgithub.comでオープンソースで行われており、どんどんバージョンアップされています。
github.com – VOICEVOX | 無料で使える中質的なテキスト読み上げソフトウェア
最初は、Raspberry Pi にCOREをインストールして利用しようと目論んでいましたが、悪戦苦闘した結果、断念しました。今回は、Windowsでエンジンを起動しておき、Raspberry Pi からエンジンにリクエストを送って、音声合成結果を受け取って再生するという方法を採用したいと思います。
Windowsのインストーラであれば、全てが含まれたソフトウェアをダウンロードしてすぐに使えます。
ダウンロードのページからWindows版をダウンロードしてインストールします。おそらく躓く要素はないのでインストール手順などは割愛します。
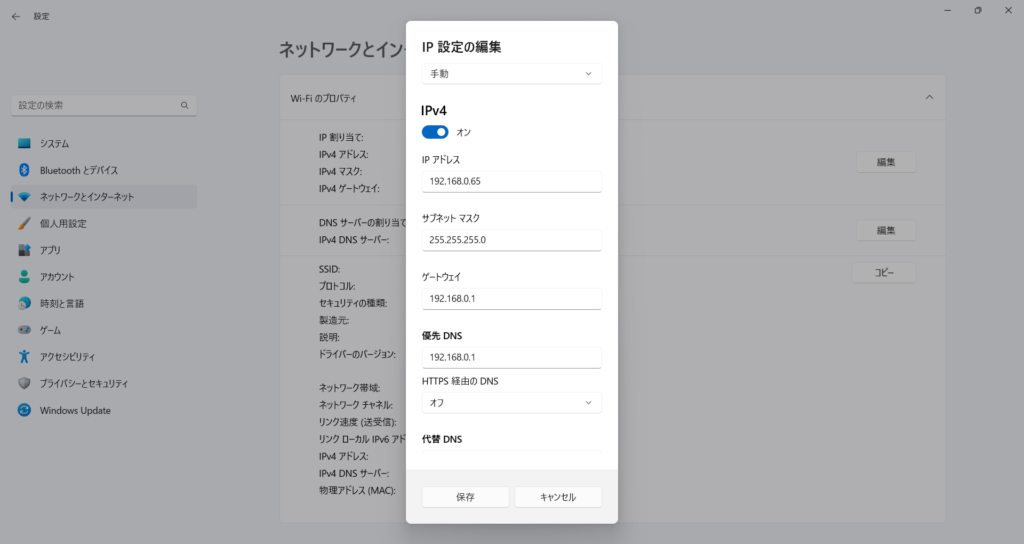
サーバとして動作させるためIPアドレスを固定します。私の環境では「192.168.0.65」にしました。
VOICEVOXエンジンの起動
他のPCからアクセスできるように以下のコマンドでVOICEVOXエンジンを起動します。コマンドプロンプトを起動して以下のコマンドを入力します。起動時に「–host」でIPアドレスを指定します。他にポートも指定できますが、デフォルトの「20021」のまま実行します。
> cd AppData\Local\Programs\VOICEVOX
> run.exe --host 192.168.0.65以下のようなコマンドが表示され実行されます。
Warning: cpu_num_threads is set to 0. ( The library leaves the decision to the synthesis runtime )
2023-04-11T02:16:14.080446Z INFO voicevox_core::publish: 検出されたGPU (DirectMLには1番目のGPUが使われます):
2023-04-11T02:16:14.084793Z INFO voicevox_core::publish: - "Intel(R) Iris(R) Xe Graphics" (128 MiB)
2023-04-11T02:16:14.085141Z INFO voicevox_core::publish: - "Microsoft Basic Render Driver" (0 B)
INFO: Started server process [13912]
INFO: Waiting for application startup.
reading C:\Users\chikuma\AppData\Local\voicevox-engine\voicevox-engine\tmp7tt5cxvu ... 62
emitting double-array: 100% |###########################################|
done!
INFO: Application startup complete.
INFO: Uvicorn running on http://192.168.0.65:50021 (Press CTRL+C to quit)
終了させるときは、キーボードから「Ctrl+C」を打つみたいですね。
Raspberry Pi で音声変換を行ってみる
今度は、Raspberry Pi からアクセスしてみます。ブラウザを起動してURLに「http://192.168.0.65:20021/docs」を入力してみます。
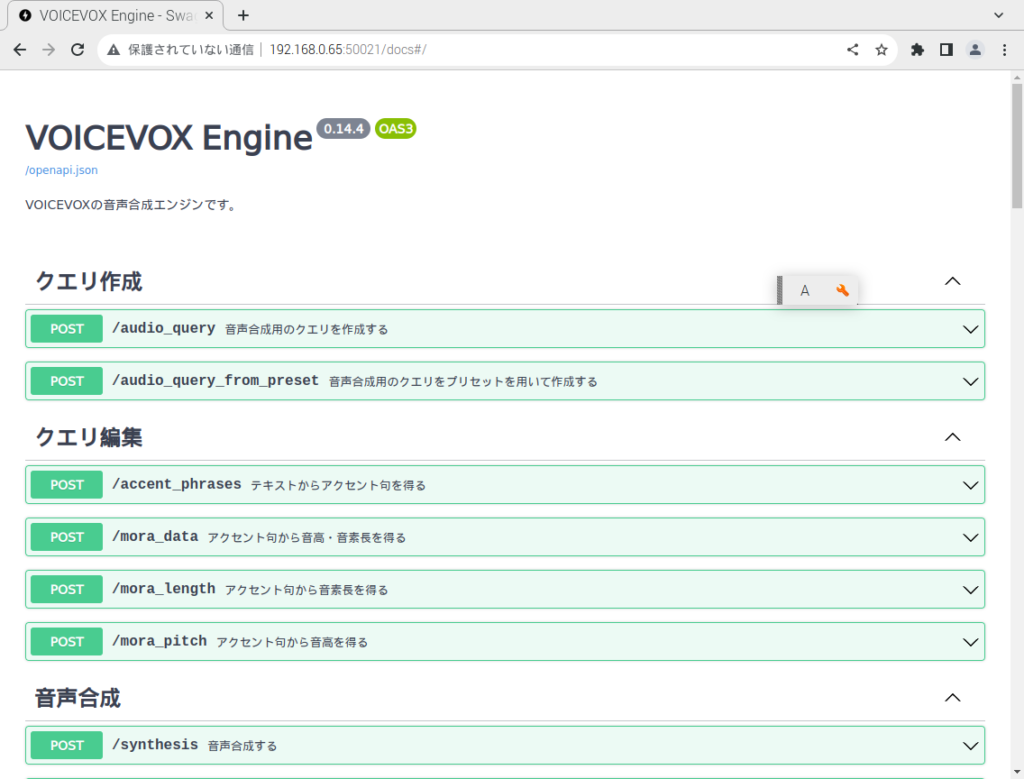
アクセスできました。これで音声変換の準備は整いました。Raspberry Pi に小型のスピーカーを繋いで実際に声をだせるか試してみたいと思います。

それでは、音声変換を動かしてみたいと思います。ターミナルで「curl」を使ってHTTP通信をします。
$ echo -n "おはようございます。わたしは、アウロ1号、です" > text.txt
$ curl -s -X POST "192.168.0.65:20021/audio_query?speaker=23" --get --data-urlencode text@text.txt > query.json
$ curl -s -H "Content-Type:application/json" -X POST -d @query.json "192.168.0.65:50021/synthesis?speaker=23" > audio.wavまず、echo で音声テキストを作成します。続いて音声合成用のクエリ(テキストを音声合成しやすい形に整形したもの)を作成します。ちなみにこのクエリを編集してアクセントなどを変更することもできます。作成したクエリをエンジンに渡して、音声合成(synthesis)をしてもらいます。
ちなみに「アウロ1号」というのは、作成中のロボットの名前です。
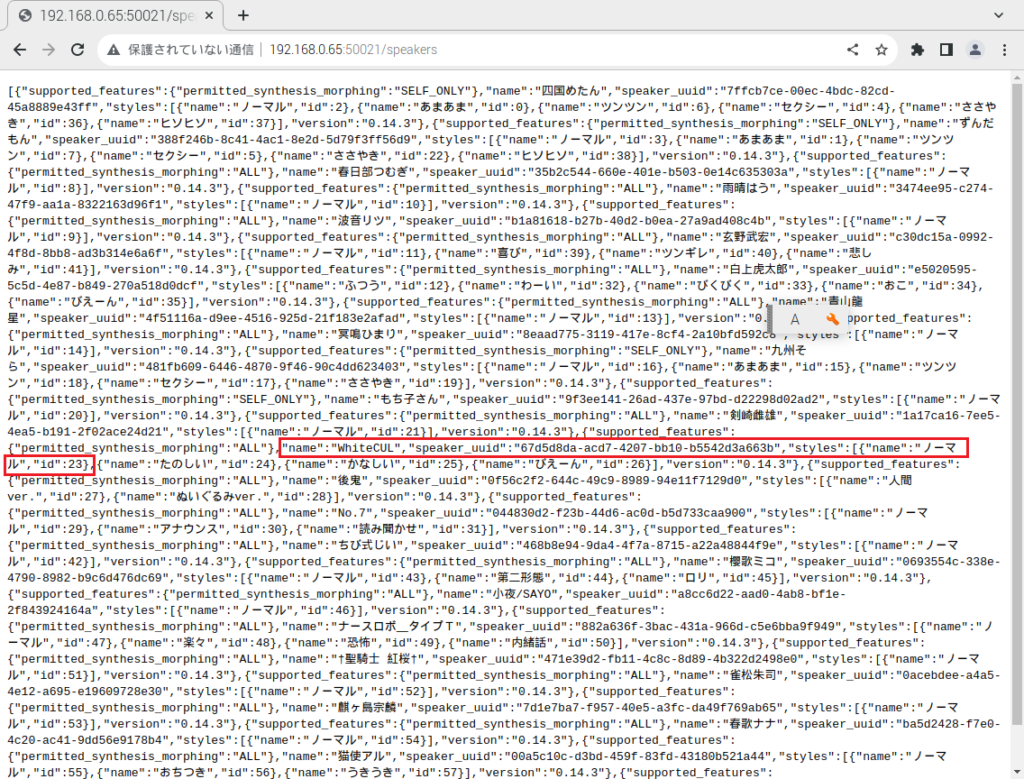
今回、利用したのは、「WhiteCUL」さんです。ロボットの声に採用したいと思います。WhiteLCUのspeaker_id は「23」です。スピーカIDが知りたい場合は、「http://192.168.0.65:20041/speakers」を開くと改行なく羅列されていますが、知ることはできます。WhiteCULさんは下の赤枠で囲ったあたりに書いてあります。「ノーマル」の他にも「たのしい」や
VOICEVOXは、無料ですが利用規約がありクレジットを表示するというお約束です。下記ページのWhiteCULさんにしゃべってもらいました。
実際のテスト音声が以下になります。
なんだか1つ大きなものを得た気がします。
以上


コメント